|
|
||||||||
 |
||||||||
|
|
||||||||
|
||||||||
|
|
||||||||
Recent progress in 3D object generation has been fueled by the strong priors offered by diffusion models. However, existing models are tailored to specific tasks, accommodating only one modality at a time and necessitating retraining to change modalities. Given an image-to-3D model and a text prompt, a naive approach is to convert text prompts to images and then use the image-to-3D model for generation. This approach is both time-consuming and labor-intensive, resulting in unavoidable information loss during modality conversion. To address this, we introduce XBind, a unified framework for any-to-3D generation using cross-modal pre-alignment techniques. XBind integrates an multimodal-aligned encoder with pre-trained diffusion models to generate 3D objects from any modalities, including text, images, and audio. We subsequently present a novel loss function, termed Modality Similarity (MS) Loss, which aligns the embeddings of the modality prompts and the rendered images, facilitating improved alignment of the 3D objects with multiple modalities. Additionally, Hybrid Diffusion Supervision combined with a Three-Phase Optimization process improves the quality of the generated 3D objects. Extensive experiments showcase XBind’s broad generation capabilities in any-to-3D scenarios. To our knowledge, this is the first method to generate 3D objects from any modality prompts.
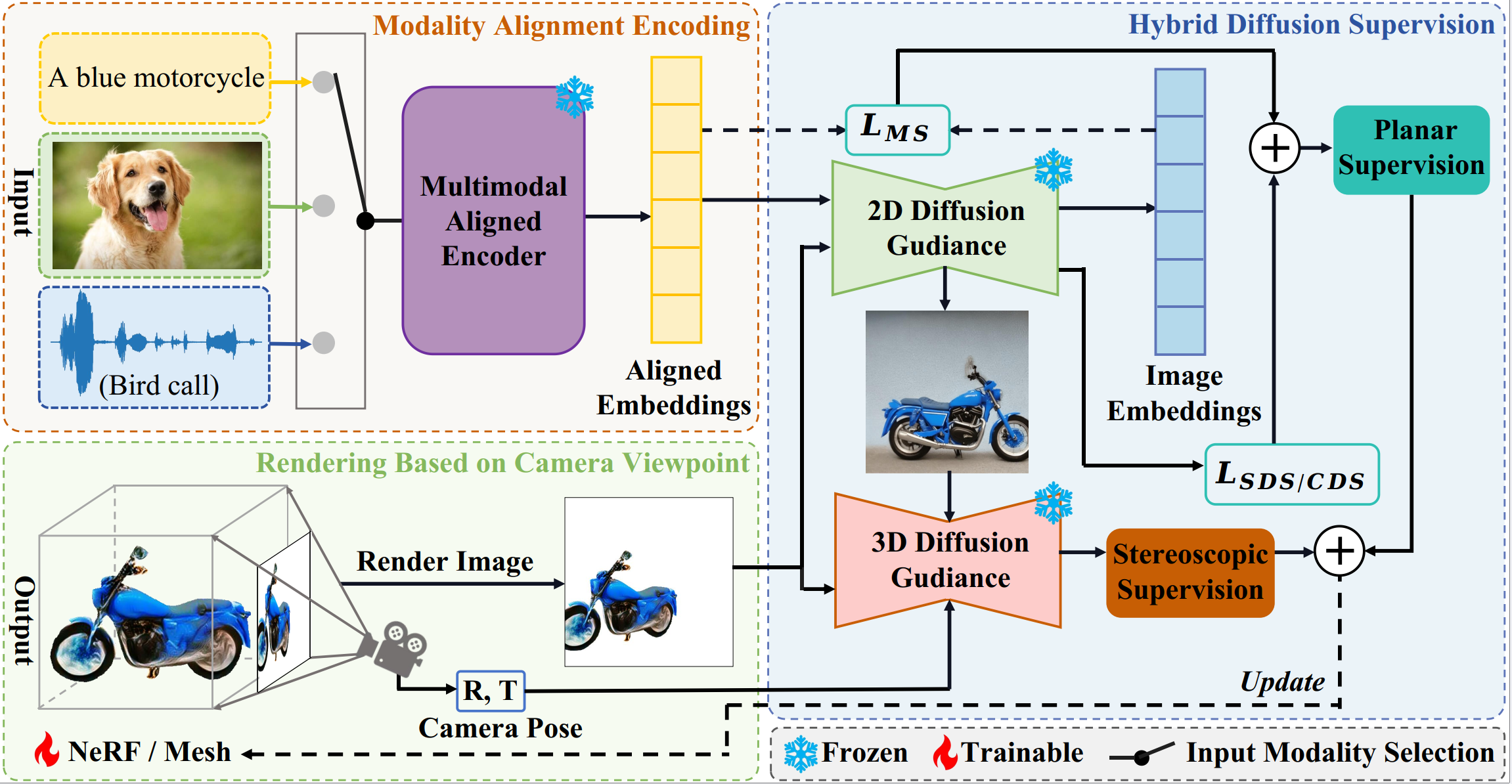
Overview of XBind. Our method can accept multi-modal inputs and generate high-quality 3D objects conditioned on these modalities. Our framework utilizes a coarse-to-fine strategy, dividing the model optimization into three phases. The first phase involves coarse 3D object generation using NERF as the 3D representation. XBind first encodes the input modality using a multimodal-aligned encoder, mapping it into a shared modality space. This aligned modality is then used as a condition for both 2D and 3D diffusion models. XBind then leverages Hybrid Diffusion Supervision, which includes Planar and Stereoscopic supervision, to optimize the NERF, generating a coarse but consistent 3D object. In the second phase, geometry optimization, the model extracts the NERF representation as a DMTET and refines the geometric details of the 3D mesh using the same supervision. The third phase focuses on texture optimization, where the model enhances texture details with Hybrid Diffusion Supervision. After completing these phases, XBind produces high-quality 3D objects with consistent and rich geometric and textural details.
XBind accepts input in any modality, including text, images, and audio, to generate high-fidelity 3D objects with detailed geometry and texture that align with the modality prompts. All 3D objects were generated on a single Nvidia RTX 3090 GPU using the PyTorch library.
We present the high-quality results of 3D object generation guided by text prompts using XBind.
|
|
|
|
|
||
|
|
|
|
XBind can also take images as input to generate high-fidelity 3D objects. Unlike most image-to-3D models, which focus on precise reconstruction, XBind emphasizes generation. As a result, our approach doesn't aim to replicate the scenes in the images exactly but instead creates new 3D objects that capture the style of the input images.

|
|
|
|
||

|
|
|
XBind can take audio input to generate high-quality 3D objects that correspond to the audio information, offering new research avenues in the relatively unexplored field of audio-to-3D generation.
|
|
||
|
||
|
|
||
As a pioneering work in Any-to-3D generation, we developed three baseline models for comparative analysis. These models utilize different diffusion models and loss functions across three phases of 3D object optimization. First, ZeroStableCDS-3D employs Zero-1-to-3 and Stable unCLIP as 3D and 2D diffusion priors, respectively, with CDS loss used for supervision in all phases. Second, StableSDS-3D uses only Stable unCLIP as the 2D diffusion prior, applying SDS loss throughout all phases. Finally, ZeroSDS-3D relies solely on Zero-1-to-3 as the 3D diffusion prior, with SDS loss applied in every phase.
| Condition | ZeroStableCDS-3D | StableSDS-3D | ZeroSDS-3D | XBind | |
|
|
|
||||
|
|||||

|
|
||||
|
|||||
|
|
|||||
In the text-to-3D task, we compared XBind's 3D generation results with State-of-the-Art methods, including DreamFusion, Magic3D, Fantasia3D, and ProlificDreamer. The results demonstrate that XBind can generate high-quality 3D objects with rich geometry and texture while maintaining good 3D consistency, outperforming the SOTA methods in terms of performance.
| DreamFusion | Magic3D | Fantasia3D | ProlificDreamer | XBind |
| Beautiful, intricate butterfly | ||||
| A blue motorcycle | ||||
| A knight chopping wood | ||||
| A photo of the Donut | ||||
| A silver candelabra has candles lit | ||||
| A kingfisher bird | ||||
| A small saguaro cactus planted in a clay pot | ||||